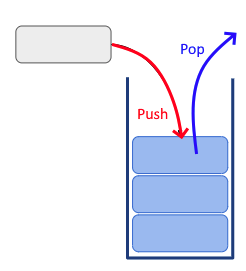
연결리스트
노드로 감싸진 요소를 인접한 메모리 위치가 아닌 독립적으로 저장한다.
각 노드는 next 또는 next,prev 라는 포인터로 서로 연결된 선형적인 자료구조
- 참조: O(n)
- 탐색: O(n)
- 삽입 / 삭제: O(1)
연결리스트에 접근하기 위해서는 첫 노드를 가리키는 head가 반드시 있어야 한다.
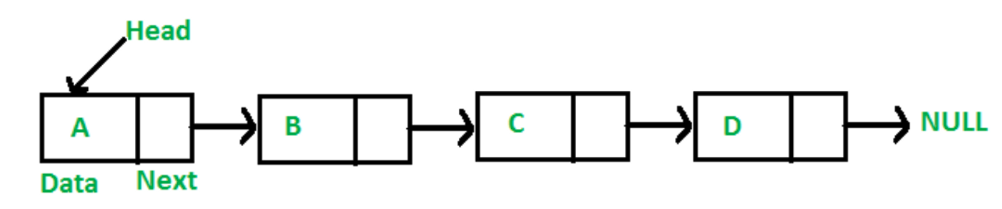
노드란, data와 next로 이루어진 구조체이다. 값을 담고 있는 data, 노드와 노드를 잇는 next라는 포인터로 이루어져 있다.
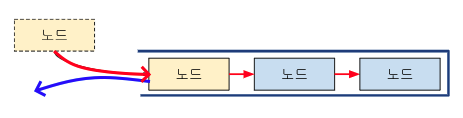
싱글연결리스트
next 포인터만 존재하여 한 방향으로만 데이터가 연결된다.
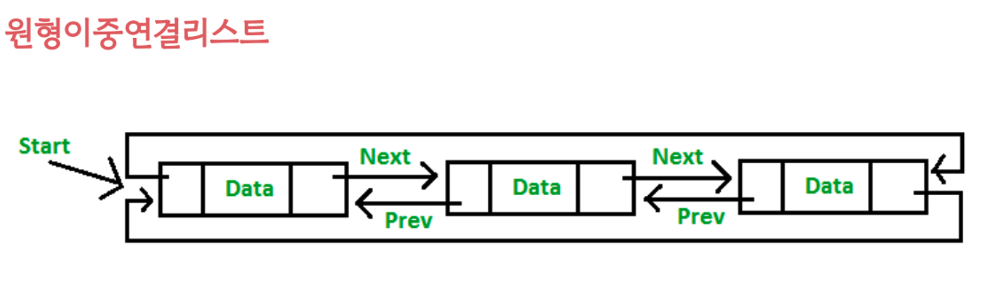
원형연결리스트
마지막 노드와 첫번째 노드가 연결되어 원을 형성한다.
싱글연결리스트 또는 이중연결리스트로 이루어진 2가지 타입의 원형 리스트가 있다.
싱글연결리스트로 구성된 원형연결리스트
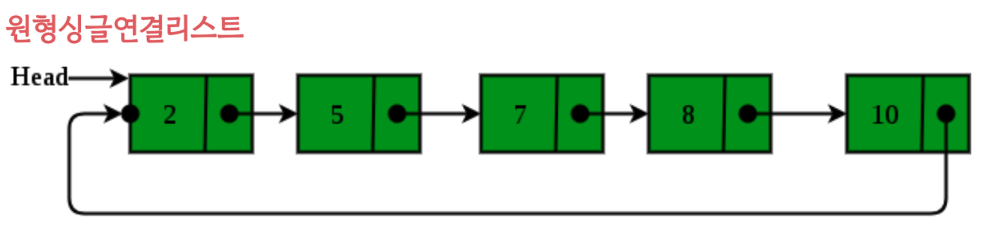
이중연결리스트로 구성된 원형연결리스트
랜덤접근과 순차적 접근
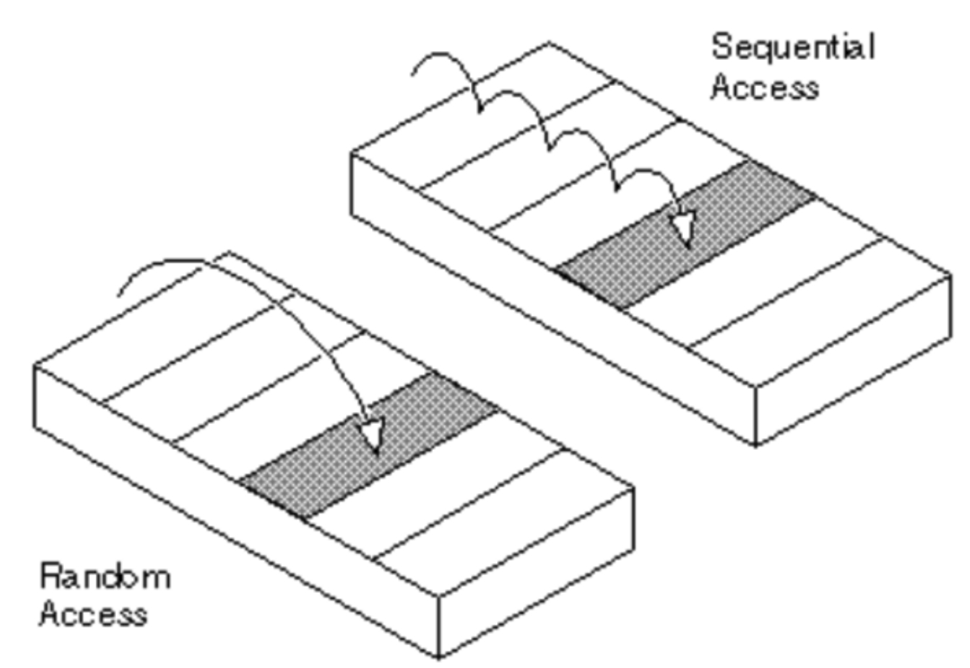
랜덤접근(random access, 직접접근)
- 동일한 시간에 배열과 같은 순차적인 데이터가 있을 때, 임의의 인덱스에 해당하는 데이터에 접근할 수 있는 기능
- vector, array는 랜덤 접근 가능하여 n번째 요소에 접근 시 O(1)
순차적 접근(squential access)
- 데이터를 저장된 순서대로 검색하며 순차적으로 접근
- 연결리스트, 스택, 큐는 순차적 접근만 가능하여 n번째 요소 접근 시 O(n)
📌 배열과 연결리스트 비교
배열
- 배열은 indexing으로 원소에 접근은 쉽다. O(1)
- 하지만 맨 끝을 제외한 위치에서 원소를 추가 / 삭제 하는 것은 연속한 메모리 공간을 확보하고 원소를 이동시켜야하므로 시간이 오래 걸린다. O(n)
연결리스트
- 연결리스트는 이전 노드들을 순차적으로 접근해야 하므로 접근은 오래 걸린다. O(n)
- 하지만 삽입 / 삭제는 노드를 생성하고 next, prev 포인터로 이전, 다음 노드만 연결해주면 되므로 시간 복잡도가 적다. O(1)
- 자료의 양이 정해져 있지 않아서 추가 및 삭제하는 일이 많은 경우 연결리스트가 적합하다.
댓글 공유